Connection of a Credit Card Machine on the Back of Spectrum Modem
From the moment the e-commerce payment systems came to existence, there have always been people who will find new ways to access someone's finances illegally. This has become a major problem in the modern era, as all transactions can easily be completed online by only entering your credit card information. Even in the 2010s, many American retail website users were the victims of online transaction fraud right before two-step verification was used for shopping online. Organizations, consumers, banks, and merchants are put at risk when a data breach leads to monetary theft and ultimately the loss of customers' loyalty along with the company's reputation.
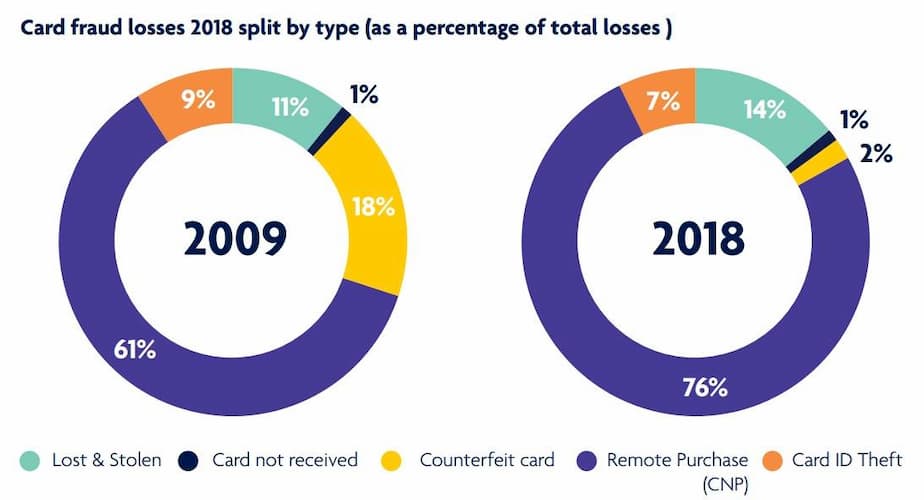
Unauthorized card operations hit an astonishing amount of 16.7 million victims in 2017. Additionally, as reported by the Federal Trade Commission (FTC), the number of credit card fraud claims in 2017 was 40% higher than the previous year's number. There were around 13,000 reported cases in California and 8,000 in Florida, which are the largest states per capita for such type of crime. The amount of money at stake will exceed approximately $30 billion by 2020. Here are some credit card fraud statistics:
What is the difference between ML Credit Card Fraud Detection and Conventional Fraud Detection?
Machine Learning-based Fraud Detection:
- Detecting fraud automatically
- Real-time streaming
- Less time needed for verification methods
- Identifying hidden correlations in data
Conventional Fraud Detection:
- The rules of making a decision on determining schemes should be set manually.
- Takes an enormous amount of time
- Multiple verification methods are needed; thus, inconvenient for the user
- Finds only obvious fraud activities

What is Credit Card Fraud Detection?
"Fraud detection is a set of activities that are taken to prevent money or property from being obtained through false pretenses."
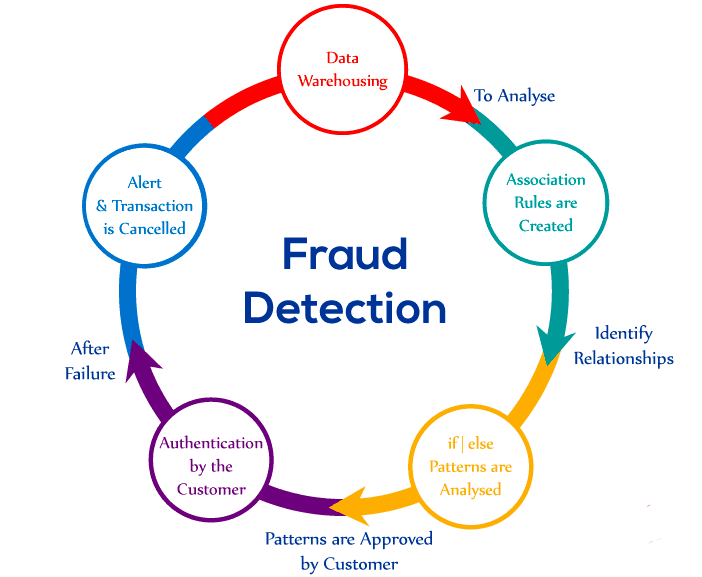
Fraud can be committed in different ways and in many industries. The majority of detection methods combine a variety of fraud detection datasets to form a connected overview of both valid and non-valid payment data to make a decision. This decision must consider IP address, geolocation, device identification, "BIN" data, global latitude/longitude, historic transaction patterns, and the actual transaction information. In practice, this means that merchants and issuers deploy analytically based responses that use internal and external data to apply a set of business rules or analytical algorithms to detect fraud.
Credit Card Fraud Detection with Machine Learning is a process of data investigation by a Data Science team and the development of a model that will provide the best results in revealing and preventing fraudulent transactions. This is achieved through bringing together all meaningful features of card users' transactions, such as Date, User Zone, Product Category, Amount, Provider, Client's Behavioral Patterns, etc. The information is then run through a subtly trained model that finds patterns and rules so that it can classify whether a transaction is fraudulent or is legitimate.
The Techniques of Credit Card Fraud and Prevention
| Rank | Category | # of Reports |
|---|---|---|
| 1 | Internet Services | 62,942 |
| 2 | Credit Cards | 51,129 |
| 3 | Healthcare | 47,410 |
| 4 | Television and Electronic Media | 38,336 |
| 5 | Foreign Money Offers and Counterfeit Check Scams | 27,443 |
| 6 | Computer Equipment and Software | 18,350 |
| 7 | Investment-Related | 14,884 |
Clone transactions.
Clone transactions are often a popular method of making transactions similar to an original one or duplicating a transaction. This can happen when an organization tries to get payment from a partner multiple times by sending the same invoice to different departments.
The conventional method of rule-based fraud detection algorithm does not work well to distinguish a fraudulent transaction from irregular or mistaken transactions. For instance, a user could click the submission button two times by accident or order the same product twice.
The better option is if a system is capable of differentiating a fraudulent transaction from one made in error. Here, Machine Learning methods would be more potent in differentiating clone transactions caused by human error and real fraud.
Account theft and suspicious transactions.
When an individual's personal information such as a Social Security number, a secret question answer, or date of birth is stolen by criminals, they can use this information to perform financial operations. A lot of fraudulent transactions are linked to identity theft, so financial fraud prevention systems should pay the most attention to creating an analysis of a user's behavior.
If there is a certain regularity in the way a client makes his payments, e. g. someone visits a certain bar once a week at the same time and always spends about $40 to $60. If the same account is used to make a payment at a bar located in another part of town and for a sum of more than $60, this behavior would be considered irregular. The next move would be to send a verification request to the card number owner in order to validate that he or she made the transaction.
Metrics such as standard deviation, averages, and high/low values are the most useful to spot irregular behavior. Separate payments are compared with personal benchmarks to identify transactions with a high standard deviation. Then, the best choice is to validate the account holder if such a deviation occurs.
False application fraud.
Application fraud is often accompanied by account/identity theft. It means that someone applies for a new credit account or credit card in another person's name. First, criminals steal the documents which will serve as supporting evidence for their fake application.
Anomaly detection helps to identify whether a transaction has any unusual patterns, such as date and time or the number of goods. If the algorithm spots such unusual behavior, the owner of the bank account will be protected by a few verification methods.
Credit Card Skimming (electronic or manual).
Credit card skimming means making an illegal copy of a credit or bank card with a device that reads and duplicates information from the original card. Fraudsters use machines named "skimmers" to extract card numbers and other credit card information, save it, and resell to criminals.
As in the case of identity theft, suspicious transactions made from a copy of an electronic or manual card will be revealed because of the information on the transaction. Classification techniques can define whether a transaction is fraudulent based on hardware, geolocation, and information about a client's behavior patterns.
Learn more about Credit Card Skimming in the video below:
Account takeover.
Fraudsters can send deceptive emails to cardholders. The messages look pretty legitimate (e.g. very similar bank URLs and trustworthy logos), as if they were sent by the bank. In reality, such a message can be used to steal someone's personal information, bank account numbers, and online passwords. If you click the wrong link or provide valuable information in response to a message from a fake bank website, within a couple of hours your bank account will be drained by the criminals into an account they hold.
To avoid this fraud model, AI-driven solutions rely on neural networks or pattern recognition. Neural networks can learn suspicious-looking patterns as well as to detect classes and clusters to use these patterns for fraud detection.
How Does Credit Card Fraud Happen?
Credit card fraud is usually caused either by card owner's negligence with his data or by a breach in a website's security. Here are some examples:
- A consumer reveals his credit card number to unfamiliar individuals.
- A card is lost or stolen and someone else uses it.
- Mail is stolen from the intended recipient and used by criminals.
- Business employees copy cards or card numbers of its owner.
- Making a counterfeit credit card.
When your card is lost or stolen, an unauthorized charge can happen; in other words, the person who finds it uses it for a purchase. Criminals can also forge your name and use the card or order some goods through a mobile phone or computer. Also, there is the problem of using a counterfeit credit card – a fake card that has the real account information that was stolen from holders. That is especially dangerous because the victims have their real cards, but do not know that someone has copied their card. Such fraudulent cards look quite legitimate and have the logos and encoded magnetic strips of the original one. Fraudulent credit cards are usually destroyed by the criminals after several successful payments, just before a victim realizes the problem and reports it.
ARE YOU INTERESTED IN LEARNING MORE ABOUT CREDIT CARD FRAUD DETECTION?
Read the Case Study that uncovers our experience in Ecommerce Fraud Detection in a real-world use case
Case Study
Credit Card Fraud Detection Systems and the Steps to Implement AI Fraud Detection Systems
Credit Card Fraud Detection Systems:
- Off-the-shelf fraud risk scores pulled from third parties (e.g. LexisNexis or MicroBilt).
- Predictive machine learning models that learn from prior data and estimate the probability of a fraudulent credit card transaction.
- Business rules that set conditions that the transaction must pass to be approved (e.g. no OFAC alert, SSN matches, below deposit/withdrawal limit, etc.).
Among these fraud analytics techniques, predictive Machine Learning models belong to smart Internet security solutions.
AI Fraud Detection System Implementation Steps:
- Data Mining. Implies classifying, grouping, and segmenting of data to search millions of transactions to find patterns and detect fraud.
- Pattern Recognition. Implies detecting the classes, clusters, and patterns of suspicious behavior. Machine Learning here represents the choice of a model/set of models that best fit a certain business problem. For example, the neural networks approach helps automatically identify the characteristics most often found in fraudulent transactions; this method is most effective if you have a lot of transaction samples.
Once the Machine Learning-driven Fraud Protection module is integrated into the E-commerce platform, it starts tracking the transactions. Whenever a user requests a transaction, it is processed for some time. Depending on the level of predicted fraud probability, there are three possible outcomes:
- If the probability is less than 10%, the transaction is allowed.
- If the probability is between 10% and 80%, an additional authentication factor (e.g. a one-time SMS code, a fingerprint, or a Secret Question) should be applied.
- If the probability is more than 80%, the transaction is frozen, so it should be processed manually.
Requirements for Payment Fraud Detection with AI-based Methods
To run an AI-driven strategy for Credit Card Fraud Analytics, a number of critical requirements should be met. These will ensure that the model reaches its best detection score.
Amount of data.
Training high-quality Machine Learning models requires significant internal historical data. That means if you do not have enough previous fraudulent and normal transactions, it would be hard to run a Machine Learning model on it because the quality of its training process depends on the quality of the inputs. Because it is rarely the case that a training set contains an equal amount of data samples in two classes, dimensionality reduction or data augmentation techniques are used for that.
Quality of data.
Models may be subject to bias based on the nature and quality of historical data. This statement means that if the platform maintainers did not collect and sort the data neatly and properly or even mixed the information of fraudulent transactions with the information of normal ones, that is likely to cause a major bias in the model's results.
The integrity of factors.
If you have enough data that is well-structured and unbiased, and if your business logic is paired nicely with the Machine Learning model, the chances are very high that fraud detection will work well for your customers and your business.
Advanced Credit Card Fraud Identification Methods and Their Advantages
Advanced Credit Card Fraud Identification Methods are split into:
- Unsupervised. Such as PCA, LOF, One-class SVM, and Isolation Forest.
- Supervised. Such as Decision Trees (e.g. XGBoost and LightGBM), Random Forest, and KNN.
We've covered the basic vision of how Machine Learning for fraud detection works. Let's now dig deeper into the exact models that make it possible.
Unsupervised.
Unsupervised Machine Learning methods use unlabeled data to find patterns and dependencies in the credit card fraud detection dataset, making it possible to group data samples by similarities without manual labeling.
PCA (Principal Component Analysis) enables the execution of an exploratory data analysis to reveal the inner structure of the data and explain its variations. PCA is one of the most popular techniques for Anomaly Detection.
PCA searches for correlations among features — which in the case of credit card transactions, could be time, location, and amount of money spent — and determines which combination of values contributes to the variability in the outcomes. Such combined feature values allow the creation of a tighter feature space named principal components.
LOF (Local Outlier Factor) is the score factor that helps understand how high the chance is for a certain data sample to be an outlier (anomaly). This is another of the most popular Anomaly Detection methods.
To calculate LOF, the number of neighboring data points is considered to figure out its density and compare it to the density of other data points. If a certain data point has a substantially low density compared to its close neighbors, it is an outlier.
One-class SVM (Support Vector Machine) is a classification algorithm that helps to identify outliers in data. This algorithm allows one to deal with imbalanced data-related issues such as Fraud Detection.
The idea behind One-class SVM is to train only on a solid amount of legitimate transactions and then identify anomalies or novelties by comparing each new data point to them.
Isolation Forest (IF) is an Anomaly Detection method from the Decision Trees family. The main idea of IF, which differentiates it from other popular outlier detection algorithms, is that it precisely detects anomalies instead of profiling the positive data points. Isolation Forest is built of Decision Trees where the separation of data points happens first because of randomly selecting a split value amidst the minimum and maximum value of the chosen feature.
Subsequently, if we have a set of legitimate transactions, the Isolation Forest algorithm will define fraudulent credit card transactions because of their values — which are often very different from the values positive transactions have (i.e. they take place further away from the normal data points in the feature space).
Supervised
Supervised ML methods use labeled data samples, so the system will then predict these labels in future unseen before data. Among supervised ML fraud identification methods, we define Decision Trees, Random Forest, KNN, and Naive Bayes.
K-Nearest Neighbors is a Classification algorithm that counts similarities based on the distance in multi-dimensional space. The data point, therefore, will be assigned the class that the nearest neighbors have.
This method is not vulnerable to noise and missing data points, which means composing larger datasets in less time. Moreover, it is quite accurate and requires less work from a developer in order to tune the model.
XGBoost (Extreme Gradient Boosting) and Light GBM (Gradient Boosting Machine) are a single type of gradient-boosted Decision Trees algorithm, which was created for speed as well as maximizing the efficiency of computing time and memory resources. This algorithm is a blending technique where new models are added to fix the errors caused by existing models.
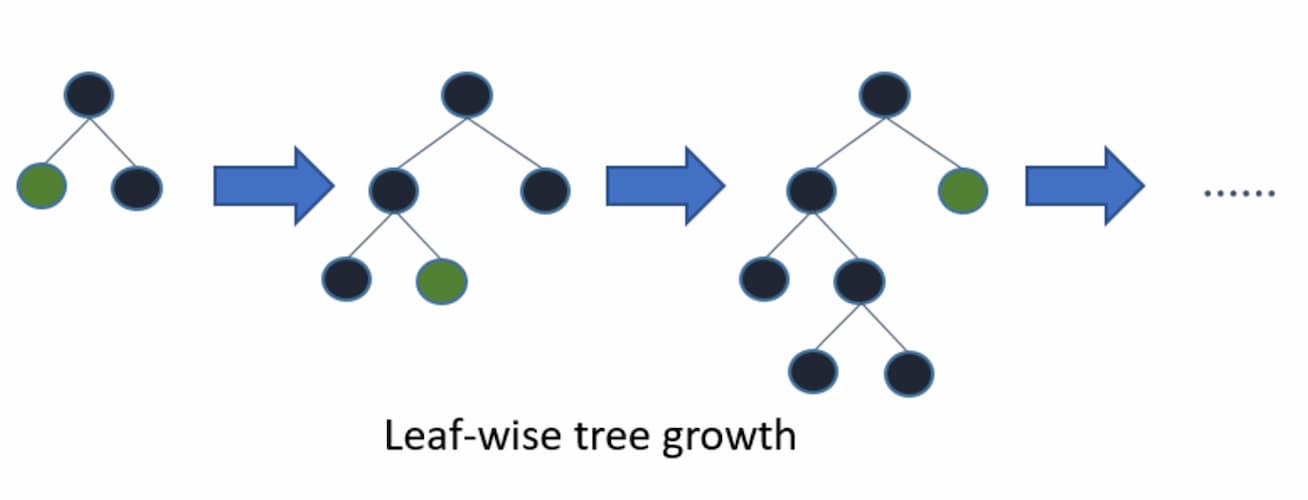
Light GBM differs from other tree-based techniques only in that it follows a leaf-wise direction to build conditions instead of a level-wise direction (fig.1,2). In general, the idea behind all tree-based gradient boosting based algorithms is the same.
To classify a transaction as a fraudulent charge, the result (probability) of many Decision Trees is summarized — whereas every future tree improves its results based on of the errors made by its predecessors.
Random Forest is a classification algorithm that is comprised of many Decision Trees. Each tree has nodes with conditions, which define the final decision based on the highest value.
The Random Forest algorithm for fraud detection and prevention has two cardinal factors that make it good at predicting things. The first one is randomness, meaning that the rows and columns of data are chosen randomly from the dataset and fit into different Decision Trees. Say Tree Number 1 receives the first 1,000 rows, Tree Number 2 receives Rows 4,000 to 5,000, and the Tree Number 3 has Rows 8,000 to 9,000.
The second factor is diversity, meaning that there's a forest of trees that contribute to the final decision instead of just one decision tree. The biggest advantage here is that this diversity decreases the chance of model overfitting, while the bias remains the same.
Different ML models can be used to detect fraud; each of them has its pros and cons. Some models are very hard to interpret, explain, and debug, but they have good accuracy (e.g. Neural Networks, Boosting, Ensembles, etc.); others are simpler, so they can be easily interpreted and visualized as a bunch of rules (e.g. Decision Trees).
It is very important to train the Fraud Detection model continuously whenever new data arrives, so new fraud schemas/patterns can be learned and fraudulent data detected as early as possible. Feel free to read our Credit Card Fraud Detection Case Study to find out how we put our Machine Learning expertise to practice.
Popular Credit Card Fraud Questions
Let's answer a few interesting questions that are often linked to Credit Card Fraud.
Who is liable for Credit Card Fraud?
In the USA, federal law (i.e. the Fair Credit Billing Act) sets a liability limit of $50 for a cardholder, regardless of the amount charged by an unauthorized user. This rule works in the event of an unsecured online connection or data breach.
If a victim reports a lost or stolen card before an unauthorized transaction happens, he or she will have no liability for charges at all.
The theft of personal information is dangerous because, although a victim is not liable for any financial losses, he or she may spend a few years dealing with all the financial and credit fraud caused by the criminals.
Do banks investigate Credit Card Fraud?
After a user notifies the bank that he or she noticed a suspicious card transaction, the bank starts a credit card fraud investigation.
The victim has to notify the bank regarding the fraudulent transaction immediately and no later than 60 days after the event. He or she must provide information about the exact amount of money lost, the date, and a description of why the transaction appears to be fraudulent. Then, the bank starts an investigation that has to be resolved in no more than 45 days. If after 10 days the bank finds out that fraud did indeed occur, the bank must reimburse the victim for the amount of money that was stolen.
The bank must notify the cardholder of the results of the investigation in writing. The cardholder has the right to ask for copies of any documents that the bank created or collected during the investigation process in the event that these documents influenced the bank's decision.
Final Word
Fraud is a major problem for the whole credit card industry that grows bigger with the increasing popularity of electronic money transfers. To effectively prevent the criminal actions that lead to the leakage of bank account information leak, skimming, counterfeit credit cards, the theft of billions of dollars annually, and the loss of reputation and customer loyalty, credit card issuers should consider the implementation of advanced Credit Card Fraud Prevention and Fraud Detection methods. Machine Learning-based methods can continuously improve the accuracy of fraud prevention based on information about each cardholder's behavior.
Further Reading
- Machine Learning Methods for Fraud Analysis of Credit Card Transactions – https://www.ijeat.org/wp-content/uploads/papers/v8i6S/F11640886S19.pdf
- Detecting Credit Card Fraud Using Machine Learning – https://towardsdatascience.com/detecting-credit-card-fraud-using-machine-learning-a3d83423d3b8
- Machine Learning Approaches for Credit Card Fraud Detection – https://www.academia.edu/36810759/Machine_Learning_Approaches_for_Credit_Card_Fraud_Detection
- Google Cloud Platform Diagram Example: Fraud Detection – https://online.visual-paradigm.com/diagrams/templates/google-cloud-platform-diagram/fraud-detection/
- Fraud Detection Using Machine Learning – https://aws.amazon.com/ru/solutions/fraud-detection-using-machine-learning/
ARE YOU INTERESTED IN DEVELOPING A CREDIT CARD FRAUD DETECTION SOLUTION?
Contact our experts to get a free consultation and time&budget estimate for your project.
Contact Us
More Insights
Connection of a Credit Card Machine on the Back of Spectrum Modem
Source: https://spd.group/machine-learning/credit-card-fraud-detection/
0 Response to "Connection of a Credit Card Machine on the Back of Spectrum Modem"
Post a Comment